Semi-Supervised Learning
Tech Terms Daily – Semi-Supervised Learning
Category — A.I. (ARTIFICIAL INTELLIGENCE)
By the WebSmarter.com Tech Tips Talk TV editorial team
1 | Why Today’s Word Matters
Artificial Intelligence (AI) systems are only as good as the data they learn from. Traditionally, training AI models has relied on supervised learning (where all training data is labeled) or unsupervised learning (where no labels are provided). The problem? Fully labeled datasets are expensive and time-consuming to create, while unlabeled data alone often lacks the guidance needed for high accuracy.
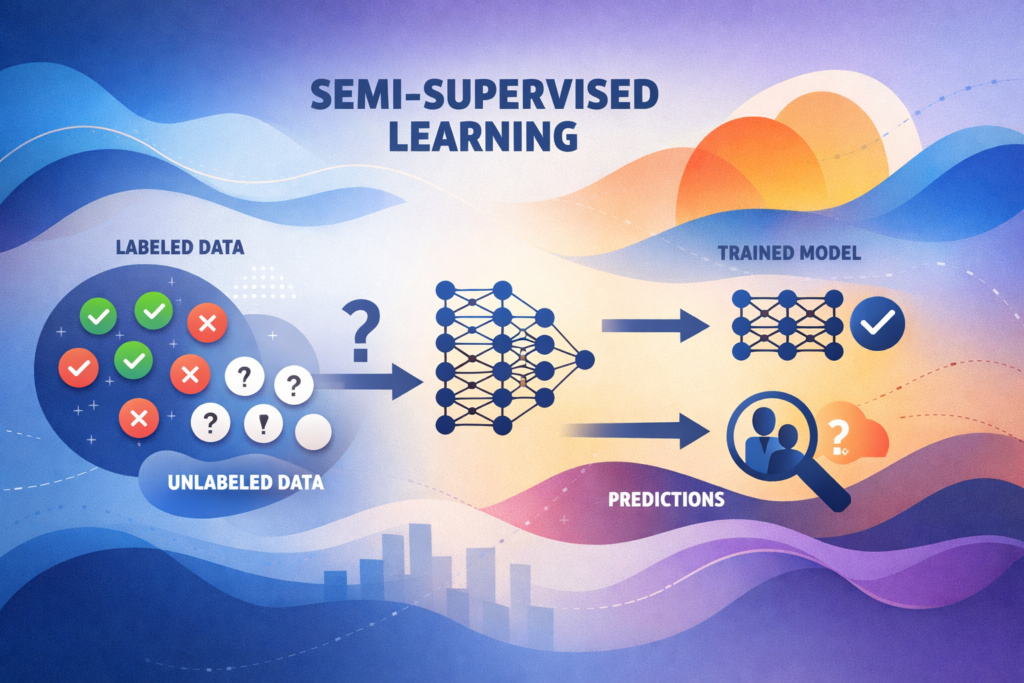
That’s where Semi-Supervised Learning (SSL) comes in—a powerful hybrid approach that uses a small amount of labeled data combined with a large amount of unlabeled data. This method strikes a balance, reducing the cost and effort of labeling while still guiding the AI toward accurate predictions.
In 2025, as industries from healthcare to cybersecurity generate massive streams of unlabeled data, SSL is becoming a crucial technique for building AI models that are both cost-efficient and performance-driven. Businesses leveraging semi-supervised learning can deploy smarter AI systems faster, without waiting for fully annotated datasets.
2 | Definition in 30 Seconds
Semi-Supervised Learning (Artificial Intelligence):
A machine learning approach that trains a model using a small set of labeled data alongside a much larger set of unlabeled data—combining the guidance of supervised learning with the scalability of unsupervised learning to improve accuracy while reducing labeling costs.
It answers four critical questions:
- How can we train models without labeling massive datasets?
- Can we still get high accuracy with limited labeled examples?
- How do we use the vast amounts of unlabeled data already available?
- How do we balance cost, speed, and model performance?
Think of semi-supervised learning as teaching with a partial answer key—the model gets enough guidance to learn patterns and generalize effectively without needing every example labeled.
3 | Why Semi-Supervised Learning Matters in AI Development
| Without SSL | With SSL |
| Requires costly, large-scale labeling | Minimizes labeling requirements |
| Slow deployment due to data preparation | Faster AI model training and rollout |
| Limited scalability for large datasets | Leverages unlimited unlabeled data |
| Accuracy drops with too little labeled data | Improved accuracy using hybrid approach |
| Inaccessible for small-to-mid businesses | Affordable AI training for more companies |
4 | Key Advantages of Semi-Supervised Learning
- Cost Efficiency – Reduce the need for expensive labeled datasets.
- Speed – Quicker time-to-market for AI solutions by cutting down labeling bottlenecks.
- Scalability – Tap into existing massive stores of unlabeled data.
- Better Generalization – Combines labeled guidance with diverse examples from unlabeled data.
- Flexibility – Useful across industries, from image recognition to fraud detection.
5 | Five-Step Blueprint for Implementing Semi-Supervised Learning
- Collect Data
- Gather both labeled and unlabeled data from your domain.
- Gather both labeled and unlabeled data from your domain.
- Choose an SSL Algorithm
- Popular methods include self-training, co-training, graph-based models, and semi-supervised GANs.
- Popular methods include self-training, co-training, graph-based models, and semi-supervised GANs.
- Train with Labeled Data First
- Use labeled data to give the model initial guidance and structure.
- Use labeled data to give the model initial guidance and structure.
- Incorporate Unlabeled Data
- Allow the model to make predictions on unlabeled data, then refine using confidence thresholds.
- Allow the model to make predictions on unlabeled data, then refine using confidence thresholds.
- Validate and Iterate
- Test the model’s accuracy on a validation set and refine the training process.
- Test the model’s accuracy on a validation set and refine the training process.
6 | Common Mistakes (and How to Fix Them)
| Mistake | Negative Effect | Quick Fix |
| Using too little labeled data | Model fails to learn key patterns | Ensure enough labeled data to provide strong initial guidance |
| Not cleaning unlabeled data | Model learns incorrect patterns | Preprocess and filter unlabeled data before training |
| Ignoring domain-specific bias | Poor performance in real-world applications | Balance datasets to reflect true conditions |
| Over-relying on pseudo-labels | Model reinforces its own errors | Use confidence thresholds to validate pseudo-labels |
| Skipping validation with real labeled data | Overestimated performance | Always test on a separate labeled validation set |
7 | Advanced Semi-Supervised Learning Tactics for 2025
- Self-Training with Pseudo-Labels – The model labels unlabeled data and retrains iteratively.
- Co-Training with Multiple Models – Two models train separately and label data for each other.
- Graph-Based SSL – Model learns relationships between labeled and unlabeled data points in a network structure.
- Consistency Regularization – Ensures the model makes stable predictions even with small data perturbations.
- Semi-Supervised Transfer Learning – Use a pre-trained model on labeled data from a similar domain, then fine-tune with your own unlabeled data.
8 | Recommended Tool Stack
| Purpose | Tool / Service | Why It Rocks |
| Machine Learning Frameworks | TensorFlow, PyTorch | Extensive SSL libraries and customization options |
| Data Labeling | Labelbox, SuperAnnotate | Streamlined labeling for initial dataset |
| AutoML with SSL Support | Google Cloud AutoML, H2O.ai | Simplifies SSL deployment for non-experts |
| Experiment Tracking | Weights & Biases, MLflow | Monitor SSL training performance |
| Large Dataset Storage | AWS S3, Google Cloud Storage | Scalable storage for labeled and unlabeled data |
9 | Case Study: Cutting AI Development Time with SSL
A WebSmarter.com healthcare client wanted to build a diagnostic image recognition model. Fully labeling their dataset of over 500,000 medical images would have taken months and cost hundreds of thousands of dollars.
Before SSL:
- Only 20,000 images were labeled by medical experts.
- Training with this small labeled set alone yielded 72% accuracy.
After WebSmarter’s SSL Implementation:
- Used labeled data to train a base model.
- Applied self-training to pseudo-label the unlabeled dataset.
- Iteratively retrained, validating with a holdout labeled set.
Result:
- Achieved 89% accuracy in 6 weeks.
- Reduced labeling costs by 65%.
- Delivered the model to production 3 months ahead of schedule.
10 | How WebSmarter.com Makes Semi-Supervised Learning Turnkey
- Data Strategy Planning – Identify the right balance of labeled and unlabeled data for your project.
- Algorithm Selection & Customization – Choose SSL techniques suited to your business problem.
- Data Cleaning & Preparation – Ensure both labeled and unlabeled datasets are high quality.
- Iterative Model Training – Refine models using SSL best practices for accuracy and efficiency.
- Deployment & Monitoring – Integrate SSL models into your workflows and track real-world performance.
11 | Wrap-Up: Smarter AI Training with Less Effort
Semi-supervised learning offers the best of both worlds—guidance from labeled data and scale from unlabeled data. It’s a practical, cost-efficient solution for organizations that want high-performing AI without massive annotation budgets.
With WebSmarter’s expertise, you can harness SSL to speed up AI development, reduce costs, and unlock the value hidden in your unlabeled datasets.
🚀 Book your Semi-Supervised Learning Consultation today and start building intelligent models that learn faster and smarter.


You must be logged in to post a comment.