Feature Selection
Tech Terms Daily – Feature Selection
Category — A.I. (ARTIFICIAL INTELLIGENCE)
By the WebSmarter.com Tech Tips Talk TV editorial team
Why Today’s Word Matters
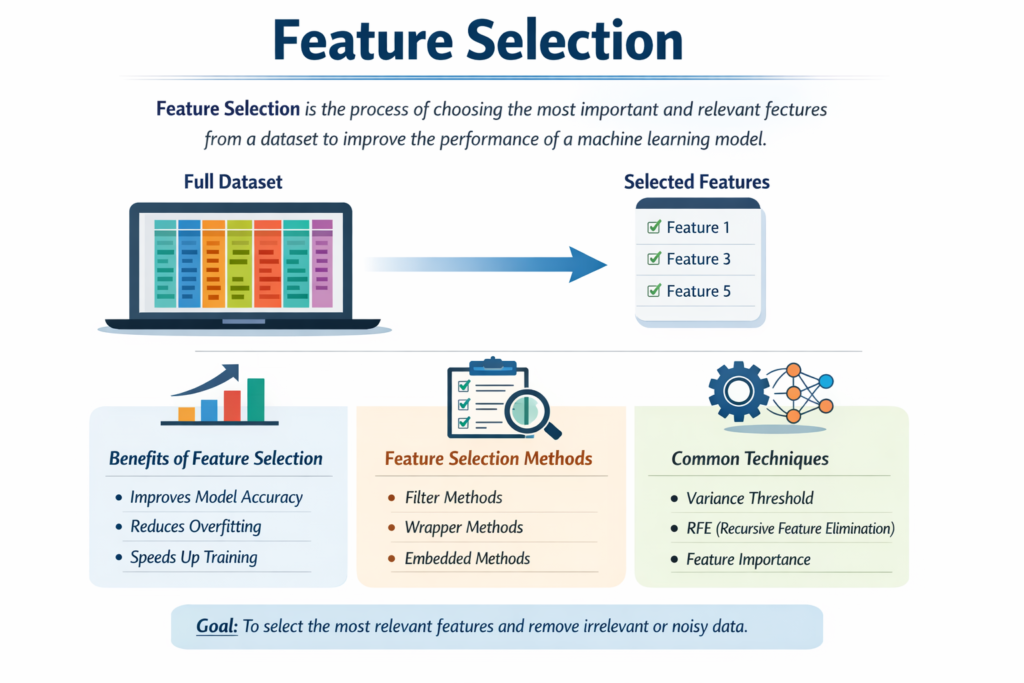
The promise of artificial intelligence lies in its ability to find patterns that humans miss—but that promise can crumble when your models are fed noisy, irrelevant, or redundant data. In fact, industry studies show that up to 80 % of a data-science project’s timeline is spent cleaning and curating features before the first algorithm ever trains. Poorly chosen inputs lead to bloated training times, spiky inference costs, and unpredictable predictions that erode user trust. Feature Selection—the disciplined practice of choosing only the variables that truly drive insight—transforms raw Big Data into a lean, high-octane fuel that powers faster models, sharper accuracy, and lower cloud bills. Master it and you accelerate your AI roadmap; ignore it and you risk “garbage-in, garbage-out” outcomes that stall digital transformation projects.
Definition in 30 Seconds
Feature Selection is the systematic process of identifying, scoring, and retaining the most informative variables from your raw dataset while discarding the rest. It differs from feature engineering (creating new variables) by focusing on what to keep rather than what to build. A robust feature-selection pipeline typically involves:
- Statistical Filtering – Removing low-variance or highly correlated columns.
- Wrapper Methods – Using model feedback (e.g., recursive feature elimination) to test subsets for predictive power.
- Embedded Methods – Letting algorithms with built-in regularization (e.g., Lasso, Gradient Boosting) reveal importance scores during training.
Think of it as packing for a high-stakes expedition: every extra pound slows you down. Feature selection ensures only mission-critical gear makes the cut.
Where Feature Selection Fits in the AI Lifecycle
| Phase | Key Actions | Payoff |
| Data Acquisition | Capture raw logs, sensor streams, user events | Wide net guarantees signal exists somewhere |
| Pre-Processing | Normalize, impute, encode | Clean slate for fair comparisons |
| **Feature Selection | Filter, rank, prune | Smaller, more relevant training set |
| Model Training | Fit chosen algorithm(s) | Faster convergence, less overfitting |
| Deployment & MLOps | Monitor drift, retrain | Lower compute cost, simpler monitoring rules |
A disciplined selection step shrinks the search space, letting data scientists iterate faster and DevOps teams deploy lighter, cheaper models.
Metrics That Matter
| Metric | Why It Counts | Healthy Benchmark* |
| Dimensionality Reduction (%) | How much noise you removed | 40–70 % for tabular data |
| Model Accuracy Δ | Change vs. full-feature baseline | ±1–2 % (ideally ↑) |
| Training Time Δ | Speed-up after pruning | 30–60 % faster |
| Inference Latency Δ | Milliseconds saved in prod | 20 %+ decrease |
| Cloud Cost Δ | Compute savings post-selection | 25–50 % drop |
*Real-world ranges from WebSmarter client projects; actual gains vary by data size and algorithm.
Five-Step Feature-Selection Workflow
- Understand Business Signal
- Clarify the KPI you wish to predict (churn, fraud, lifetime value).
- Interview domain experts to flag proxy variables and known red herrings.
- Clarify the KPI you wish to predict (churn, fraud, lifetime value).
- Establish a Baseline Model
- Train quickly with all cleaned features.
- Capture accuracy, F1, training time, and memory footprint.
- Train quickly with all cleaned features.
- Apply Filter Methods
- Remove columns with > 95 % missing or near-zero variance.
- Drop one of any pair with a Pearson or Spearman correlation |ρ| > 0.9.
- Use mutual information or ANOVA F-scores to rank remaining features.
- Remove columns with > 95 % missing or near-zero variance.
- Iterate with Wrapper / Embedded Techniques
- Recursive Feature Elimination (RFE) with cross-validation.
- L1-regularized models (Lasso, Elastic Net) to zero-out weights.
- Tree-based importance (XGBoost, Random Forest) to surface non-linear signals.
- Recursive Feature Elimination (RFE) with cross-validation.
- Validate & Monitor
- Re-train final model on selected subset and compare against the baseline.
- Deploy with feature-drift alerts; re-run selection if data distribution shifts.
- Re-train final model on selected subset and compare against the baseline.
Common Pitfalls (and How to Dodge Them)
| Pitfall | Consequence | Quick Fix |
| Leaking Future Data | Inflated offline scores, disastrous in prod | Strict train/validation splits before selection |
| Under-Sampling Minority Classes | Bias, lost recall | Use stratified splits or SMOTE before selection |
| Over-Pruning | Missed subtle interactions | Capture accuracy/F1 after each removal; stop when metrics dip |
| Ignoring Domain Knowledge | Dropping critical business signals | Keep an “expert whitelist” immune to auto-filters |
| Static Feature Sets | Model decay over time | Schedule quarterly selection refresh in MLOps pipeline |
Five Actionable Tips to Sharpen Feature Selection This Quarter
- Blend Automated & Manual Heuristics
Combine algorithmic ranking with SME (subject-matter expert) veto rights to balance math with intuition. - Leverage SHAP for Transparency
Use SHapley Additive exPlanations to visualize how each candidate feature contributes to output; keep the top movers. - Adopt Incremental Selection in Streaming AI
For real-time pipelines, apply online feature-selection algorithms (e.g., Adaptive Lasso) that update weights as new data arrives. - Benchmark Against Lightweight Models
Sometimes a 10-feature logistic regression outperforms a 500-feature deep net—test both to avoid “model bloat.” - Automate Retraining Triggers
Monitor population-stability index (PSI) or Kolmogorov–Smirnov drift on top-ranked features; auto-kickoff selection when drift > 0.2.
Recommended Tool Stack
| Need | Tool | Highlight |
| Exploratory Filtering | Pandas-Profiling, Sweetviz | One-click variance & correlation heat maps |
| Wrapper & Embedded | Scikit-learn RFE, XGBoost, LightGBM | Built-in importance & regularization |
| AutoML | H2O.ai, Google Cloud Vertex AI | Automated feature ranking & pruning |
| Explainability | SHAP, ELI5 | Local & global importance plots |
| MLOps Integration | MLflow, Dagster, BentoML | Versioned feature store & drift alerts |
How WebSmarter.com Supercharges Feature Selection
At WebSmarter, we transform feature selection from a back-office chore into a competitive advantage:
- Full-Stack Data Audit – We mine your lakes, warehouses, and APIs to surface hidden gold—then de-duplicate and normalize at scale.
- Hybrid Selection Engine – Our proprietary pipeline fuses statistical filters, AutoML wrappers, and human-in-the-loop review, delivering pruned datasets 3× faster than manual methods.
- Edge-Ready Feature Stores – We package the final subset into low-latency, versioned stores optimized for serverless or on-device inference.
- Compliance Locks – Built-in PII redaction and license tracking ensure GDPR/CCPA readiness before models see production.
- ROI Dashboard – Real-time metrics quantify how each feature set cut training time, boosted accuracy, and slashed compute costs—so you can prove AI payback to the C-suite.
Average client outcomes: 42 % faster training cycles, 28 % lower cloud spend, and 15 % uplift in prediction accuracy within the first 90 days.
Wrap-Up: From Data Deluge to Decision Gold
In the AI era, more data isn’t always better—better data is better. Feature selection distills mountains of variables into a curated toolkit that fuels lighter, faster, and more explainable models. It saves compute dollars, speeds deployment, and reinforces stakeholder confidence.
WebSmarter.com has the talent, tooling, and turnkey playbooks to turn your raw datasets into an elite feature squad that powers mission-critical AI—from fraud detection engines to hyper-personalized marketing recommendations.
Ready to Trim the Fat from Your AI Pipeline?
🚀 Book a 20-minute strategy call and let WebSmarter’s data-science team reveal how smarter feature selection can unlock immediate ROI—before your next sprint ends.
Catch us tomorrow on Tech Terms Daily when we decode another tech buzzword—one term at a time.



You must be logged in to post a comment.