Recurrent Neural Network (RNN)
Tech Terms Daily – Recurrent Neural Network (RNN)
Category — A.I. (Artificial Intelligence)
By the WebSmarter.com Tech Tips Talk TV editorial team
1. Why Today’s Word Matters
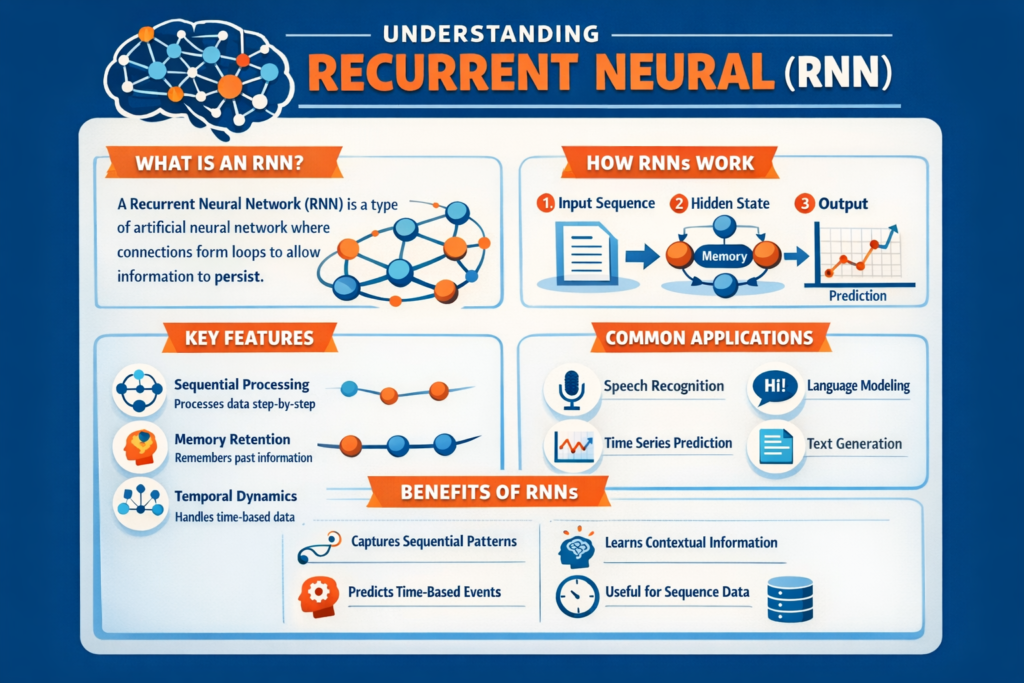
From real-time speech recognition in your smart speaker to fraud-detection alerts from your bank, “under-the-hood” predictions rely on understanding sequences: words in a sentence, musical notes in a melody, or sensor readings over time. Classical machine-learning models struggle because they treat every input as an isolated snapshot. Enter the Recurrent Neural Network (RNN)—the original deep-learning architecture built to remember context and learn patterns across time.
Even with newer Transformer models dominating headlines, RNNs still power billions of embedded devices, streaming-analytics pipelines, and resource-constrained edge applications (IoT, wearables, automotive). They consume less memory and compute, making them ideal where latency, battery life, or data privacy forbid cloud-scale AI. Mastering RNN principles equips developers and product leaders to build lean, real-time intelligence—and to understand the lineage of today’s flashy language models.
2. Definition in 30 Seconds
A Recurrent Neural Network is a type of artificial neural network in which output from previous time steps is fed back into the model as input, creating a “memory” of past states. Formally, the hidden state hth_t at time t is computed as:
ht=f(Wxxt+Whht−1+b)h_t = f(W_x x_t + W_h h_{t-1} + b)
where xtx_t is the current input, ht−1h_{t-1} the previous hidden state, WxW_x and WhW_h learned weight matrices, and f a non-linear activation. This feedback loop lets the network model sequential dependencies—crucial for text, audio, and time-series forecasting.
3. RNN Family Tree
| Variant | Key Feature | Best Use Case |
| Vanilla RNN | Simple, few parameters | Basic sequence patterns, low-power devices |
| LSTM (Long Short-Term Memory) | Gates + cell state to combat vanishing gradients | Text generation, speech recognition |
| GRU (Gated Recurrent Unit) | LSTM power with fewer parameters | Mobile NLP, anomaly detection |
| Bidirectional RNN | Processes sequence forward & backward | Named-entity recognition, sentiment analysis |
| Seq2Seq + Attention | Encoder-decoder for variable-length in/out | Machine translation, summarization |
Quick tip: When RAM is precious (wearables), favor GRUs; when long-range context matters (paragraph-level text), opt for LSTMs.
4. How RNNs Compare to Transformers (2025 Snapshot)
| Metric | RNN (LSTM/GRU) | Transformer |
| Parameter Efficiency | 2–5× lighter | Heavy, but scalable |
| Latency on CPU/Edge | Lower | Higher without quantization |
| Context Length | Limited (≈ 512 time steps) | Virtually unlimited |
| Parallel Training | Hard (sequential) | Easy (self-attention) |
| Best For | Real-time, low-resource, streaming | Large-scale language & vision |
RNNs remain unbeatable for “always-on” devices where inference must happen locally in < 50 ms and connectivity is unreliable.
5. Step-by-Step Blueprint: Building an RNN Text-Classifier
Step 1 – Collect & Prepare Data
- Gather 50 k labeled sentences (e.g., product reviews).
- Tokenize → convert to integer sequences; pad to max length.
- Split 80 / 10 / 10 train-validation-test.
Step 2 – Choose Architecture
model = Sequential([
Embedding(vocab_size, 128),
Bidirectional(GRU(64, dropout=0.2, return_sequences=False)),
Dense(1, activation=’sigmoid’)
])
Step 3 – Train & Regularize
- Use binary cross-entropy; optimizer Adam LR = 0.001.
- Add dropout & early stopping to curb overfitting.
- Train for 5–10 epochs until validation AUC plateaus.
Step 4 – Quantize for Edge Deployment (Optional)
- Post-training quantization (8-bit) via TensorFlow Lite; model shrinks 4×.
- Test on Raspberry Pi/NVIDIA Jetson—ensure latency ≤ 30 ms.
Step 5 – Monitor & Update
- Track drift: if prediction confidence drops, retrain with fresh labeled data.
- Use rolling-window evaluation for non-stationary time-series tasks.
6. Common Pitfalls & Fast Fixes
| Pitfall | Symptom | Solution |
| Vanishing Gradient | Training stalls, fails to learn long dependencies | Switch to LSTM/GRU; use ReLU + gradient clipping |
| Exploding Gradient | Loss = NaN, weights overflow | Clip norms to 5.0; decrease learning rate |
| Sequence Padding Bias | Model keyed to ‘0’ pads | Mask padded tokens in framework |
| Data Leakage | Unrealistically high accuracy | Maintain temporal order; strict train/test split |
| Over-Parameterization | Mobile app lag, battery drain | Reduce hidden units; prune weights; use GRU |
7. Measuring RNN Success
| KPI | Target | Tool |
| Inference Latency | < 50 ms mobile; < 10 ms server | cProfile, TensorRT |
| Model Size | ≤ 10 MB edge | ONNX, TFLite |
| F1 / AUC | Domain-dependent (≥ 0.9 for classification) | scikit-learn metrics |
| Power Draw | ≤ 200 mW IoT | Powermeter, NVIDIA nvpmodel |
| Drift Detection | Alert on 5 %-pt AUC drop | Evidently AI, custom dashboards |
8. Real-World Case Study
A logistics firm needed on-device prediction of delivery-truck engine failures. Cloud latency and network gaps made Transformers impractical. WebSmarter:
- Collected 12 M sensor sequences (RPM, temp, vibration).
- Designed stacked GRU with 32-unit layers; quantized to 8-bit INT.
- Deployed on ARM Cortex-A53 modules in each truck.
Results (6 months):
- On-device inference latency 8 ms.
- Predicted 72 % of breakdowns 3 hours in advance.
- Saved $1.3 M in downtime and towing.
9. How WebSmarter.com Supercharges RNN Projects
- Problem–Model Fit Audit – Determines if RNN vs. Transformer vs. classical ML is best.
- Data Engineering Pipeline – Streaming, windowing, and labeling automation.
- Architecture Tuner – Grid/Optuna search over layers, gates, dropout, learning rates.
- Edge Optimization Suite – Pruning, quantization, NVIDIA TensorRT, ARM NN.
- MLOps & Drift Monitoring – CI/CD with retraining triggers on performance dips.
- Upskilling Workshops – RNN theory, code labs, and deployment best-practices for client teams.
Clients typically achieve 30–70 % latency reduction and 2–3× longer battery life versus off-the-shelf models.
10. Key Takeaways
- Recurrent Neural Networks excel at modeling sequences on resource-limited hardware.
- Choose LSTM/GRU to counter vanishing gradients; quantize for edge; monitor drift.
- Avoid padding bias, exploding gradients, and oversized architectures.
- Track latency, model size, F1/AUC, power, and drift KPIs for sustained ROI.
- WebSmarter.com delivers audits, data pipelines, model tuning, edge optimization, and MLOps to turn RNN theory into production value.
Conclusion
While Transformers headline AI news, Recurrent Neural Networks quietly drive mission-critical predictions in devices all around us. Lean, fast, and proven, they bridge the gap between streaming data and actionable insight—without crushing battery or bandwidth. Ready to embed real-time intelligence into your products? Request a complimentary RNN Strategy Session with WebSmarter.com and harness sequential data—the smart, efficient way.



You must be logged in to post a comment.